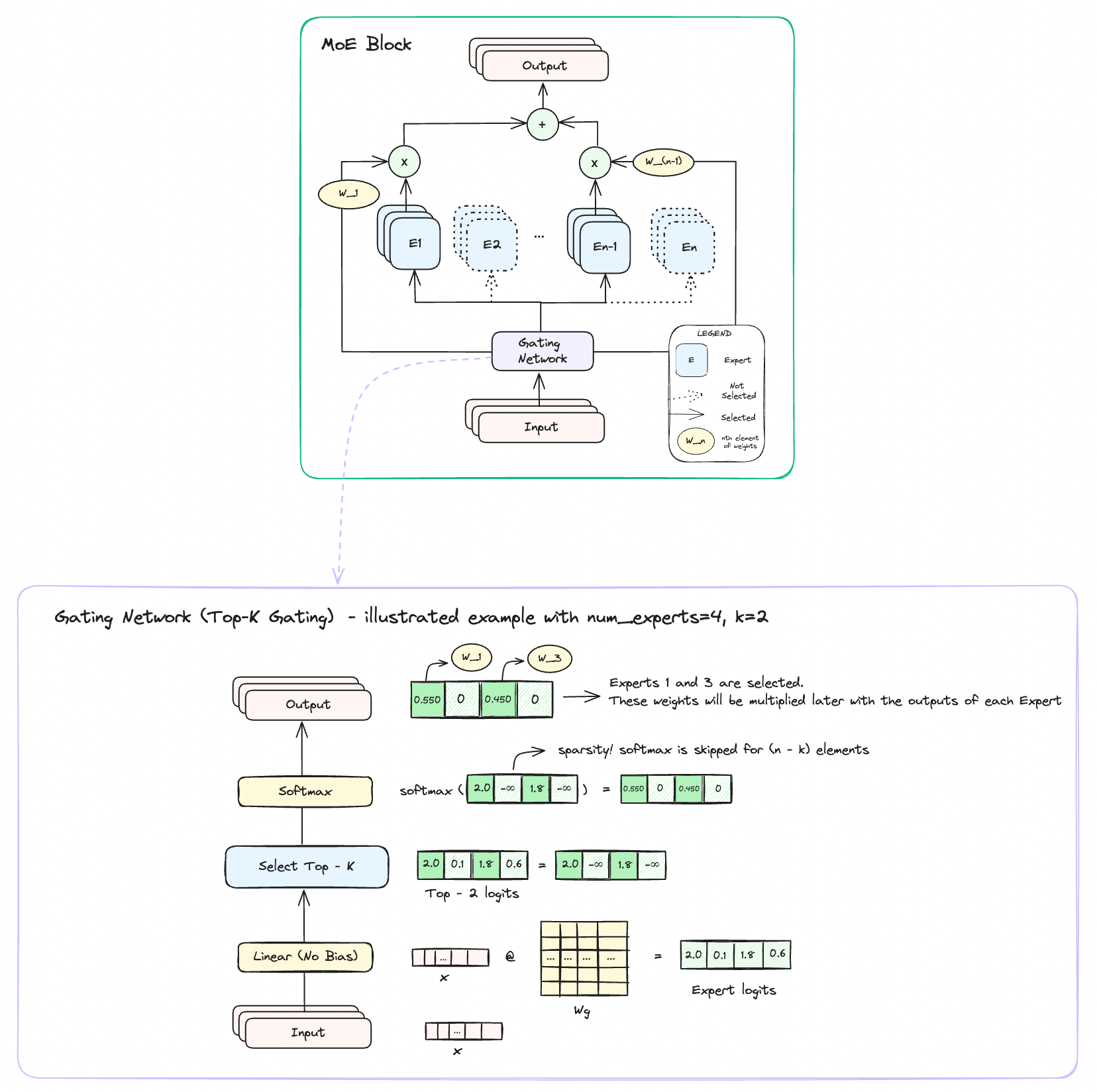
"[MoE] consists of a number of experts, each a simple feed-forward NN, and a trainable gating network which selects a sparse combination of the experts to process each input (Shazeer, 2017)...[the MoE selects] a potentially different combination of experts at each [token]. The different experts tend to become highly specialized based on syntax and semantics."
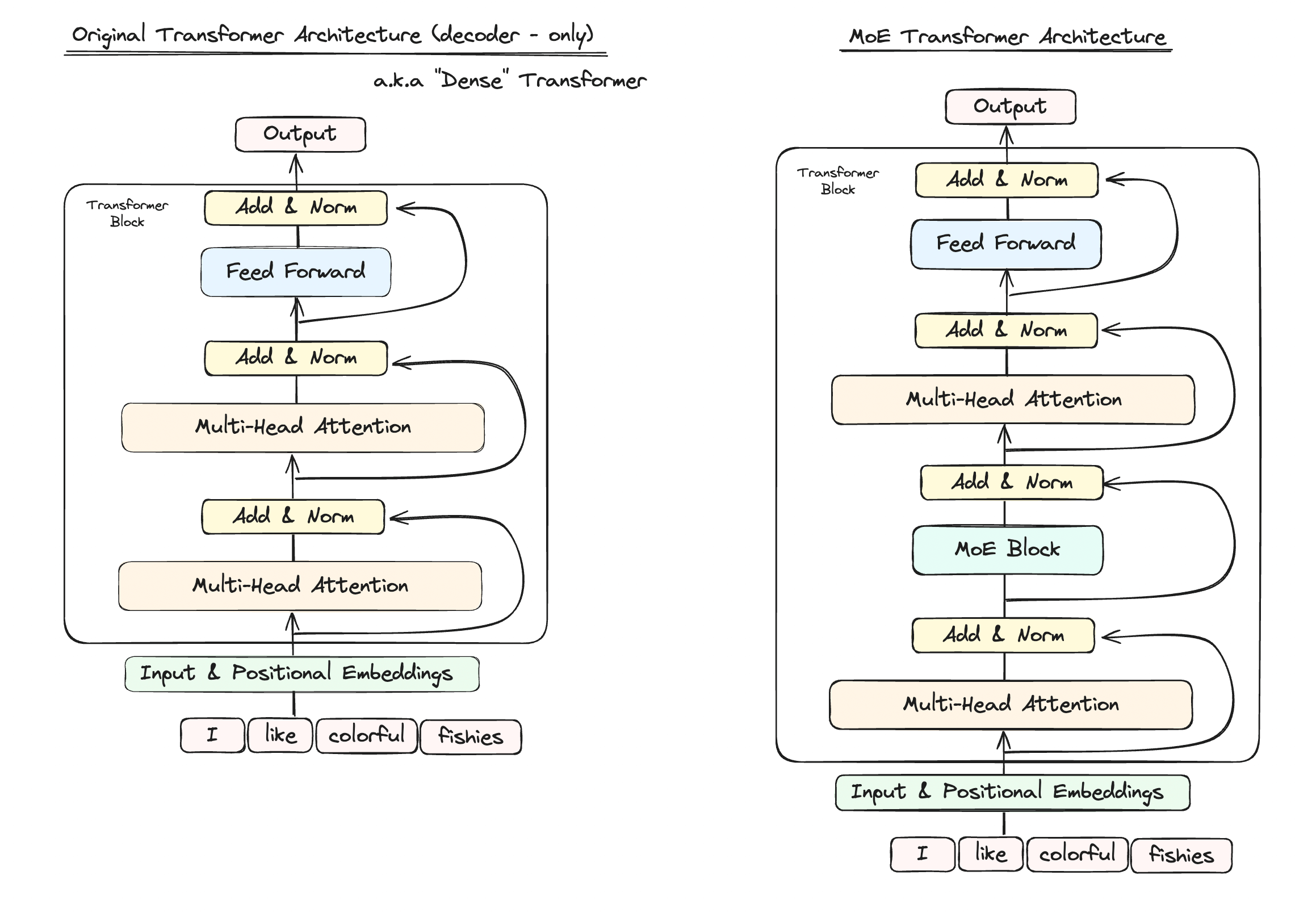
Key ideas used in the MoEs are sparsity, parallelism, and meta-learning.
Here is a single MoE block and an example gating network inside of it.
MoE Benefits:
1. Parallelism
- Each expert learns to "specialize" in one "type" of data (e.g. Expert 1 focuses on cats while Expert 2 focuses on dogs for a MoE vision classifier).
- This allows for increased throughput as different types of data are concurrently worked on by multiple experts at once.
2. Efficient Parameter Usage with Sparsity
- While dense transformers utilize large portions of their total weights during training & inference, MoE transformers learn to selectively activate subsets of the model weights during training 7 inference.
- This allows light-weight, but powerful models to emerge.
3. Meta-Learning
- Classical conditional computation methods often used human-made heuristics for the model to work with, effectively decreasing their abilities to generalize to internet-scale datasets (e.g. most conditional computation vision models were often benchmarked with datasets only up to 600,000 images).
- With MoE transformers, the gating network is jointly trained along with the experts using back-prop, effectively decreasing the bias that may come with human-made heuristics.
- ⇒ The question then becomes one of data-quality: "What is good data that provides the most information during training?"
4. Energy-Efficiency
- Sparsity of MoEs naturally saves energy usage both during training and inference, which decreases model training and upkeep costs along with reducing carbon footprints.
- Decreased number of activated parameters both during training and inference means decreased use of electricity due to less computation.
- GLaM, an early MoE LLM, used only ⅓ energy and ½ FLOPs for inference to be on par with GPT-3.
Miscellaneous:
Balancing of Expert Importance:
- To prevent converging to a state where only a few experts solve everything, an extra loss term(Limportance) is included to make sure each expert is weighted equally in importance.
Preventing Synchronization Overheads:
- Effective parallelism comes from having balanced loads distributed to each component. If Expert 1 takes in 100 examples while Expert 2 takes only 1, there is a synchronization overhead.
- To prevent this, another loss term(Lload) is added, which reinforces Experts to have approximately equal number of examples.
Downsides:
Higher Risk of Training Instability:
- Sparsity is a double-edged sword where it theoretically creates many discontinuities that result in NaNs or Infs.
- Early MoE implementations merely skipped weight updates if there were NaNs or Infs(GLaM; Du, 2017) and reverted training back to the previous checkpoint.
- This is another reason why large pre-training datasets were needed.
Need Large Batch Sizes:
- Larger batch sizes are needed to cover the sparsity that MoEs bring.
As a result, larger pre-training datasets are needed to train.
Need Many GPUs:
- Though they don't have to be hundreds of A100s, MoEs take advantage of high parallelism, which assumes you have access to many GPU devices to split computations across.
Closing Thoughts:
Scaling in low-resource environments
I don't think scaling is limited only to compute-rich places like google, meta, openai, etc. At the heart of scaling techniques is the effective usage of parallelism and GPU programming that leverages the characteristics of GPUs. And low-compute environments are places that need to pay attention to these the most.
It's easy to get discouraged by the sheer number of parameters these MoE models carry, but they carry ideas that we should be asking in academia:
- "Are we using the GPUs that we have to the max? How do we increase GPU utilization?"
- "How can we train a better model with less data? What are the metrics for good data?"
References
[1] Shazeer et al. 2017. "Outgrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer."